Snowflake 클러스터링 키 및 클러스터링된 테이블
Snowflake는 대규모 데이터를 효율적으로 관리하고 처리할 수 있도록 다양한 최적화 기법을 제공합니다. 그 중 하나가 클러스터링 키(Clustering Key)와 클러스터링된 테이블입니다. 이 포스팅에서는 클러스터링 키의 개념과 클러스터링된 테이블의 이점을 살펴보고, 이를 설정하는 방법과 고려사항을 다루겠습니다.
1. 클러스터링 키(Clustering Key)란?
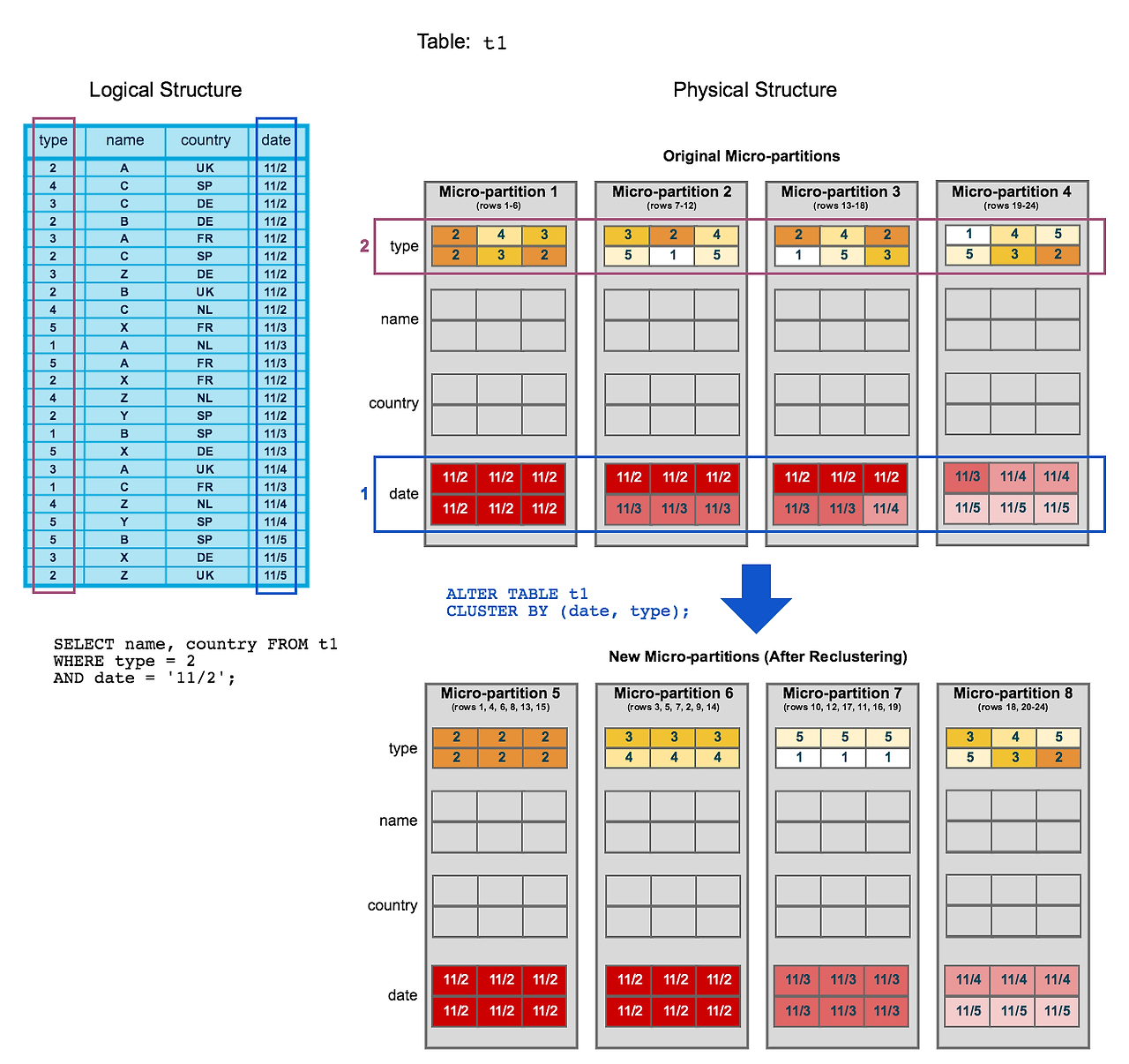
클러스터링 키(Clustering Key)는 테이블의 데이터를 특정 열을 기준으로 동일한 마이크로 파티션(Micro Partition)에 배치하도록 명시적으로 지정하는 기법입니다. 이를 통해 데이터가 물리적으로 정렬되고, 쿼리 성능을 최적화할 수 있습니다.
기본적으로 Snowflake는 테이블에 대해 자동으로 데이터를 클러스터링하지만, 데이터가 대규모로 증가하고 DML 작업(INSERT, UPDATE, DELETE)이 빈번해지면 클러스터링 성능이 저하될 수 있습니다. 이때 클러스터링 키를 정의하여 성능을 개선할 수 있습니다.
2. 클러스터링 키의 이점
클러스터링 키를 사용하면 다음과 같은 이점이 있습니다:
- 쿼리 성능 향상: 필터링 조건과 일치하지 않는 데이터를 건너뛰기(Skip Scan)하여 쿼리 성능이 향상됩니다.
- 데이터 압축 효율성 증가: 클러스터링된 열은 더 높은 비율로 압축이 가능하여 저장 공간을 절약할 수 있습니다.
- 자동 유지 관리: 클러스터링 키를 정의한 이후에는 Snowflake가 자동으로 데이터를 최적화하여 클러스터링 성능을 유지합니다.
3. 클러스터링 키 선택 전략
클러스터링 키를 선택할 때는 다음과 같은 전략을 따르는 것이 좋습니다:
- 자주 사용되는 필터 조건: 쿼리에서 자주 사용되는 필터 열을 클러스터링 키로 선택하면 성능이 크게 향상됩니다. 예를 들어, 날짜 필터가 자주 사용된다면 date 열을 클러스터링 키로 설정하는 것이 유리합니다.
- 조인 조건: 자주 조인되는 열을 클러스터링 키로 설정하면 조인 성능도 개선됩니다.
- 카디널리티(고유 값의 수): 클러스터링 키는 너무 높은 카디널리티를 가진 열에 적용하기보다는 적당한 카디널리티의 열에 적용하는 것이 바람직합니다. 카디널리티가 낮을수록 효율적이며, 클러스터링 유지 비용도 절감할 수 있습니다.
4. 클러스터링된 테이블 정의하기
클러스터링 키는 테이블 생성 시 CLUSTER BY 절을 사용하여 정의할 수 있습니다. 예를 들어, 다음과 같이 date와 id 열을 기준으로 테이블을 클러스터링할 수 있습니다:
CREATE TABLE sales ( sale_id INT, sale_date DATE, sale_amount DECIMAL )
CLUSTER BY (sale_date, sale_id);
5. 클러스터링된 테이블의 유지 관리
Snowflake는 클러스터링된 테이블을 자동으로 재클러스터링합니다. 즉, DML 작업(INSERT, UPDATE, DELETE)이 빈번하게 발생해도 Snowflake가 자동으로 데이터를 다시 클러스터링하여 성능을 유지합니다.
그러나 수동으로 재클러스터링을 수행할 수도 있으며, 이를 통해 원하는 시점에 클러스터링 상태를 최적화할 수 있습니다.
6. 재클러스터링의 비용 고려
클러스터링 및 재클러스터링 작업은 Snowflake의 컴퓨팅 리소스와 크레딧을 소모합니다. 테이블이 크고 자주 변경될수록 클러스터링 유지 비용이 증가할 수 있습니다. 따라서, 클러스터링은 자주 쿼리되지만 자주 업데이트되지 않는 테이블에 가장 적합합니다.
7. 클러스터링 키 설정 예시
클러스터링 키는 테이블 생성 후에도 ALTER TABLE 명령을 사용해 설정할 수 있습니다. 예를 들어, 기존 테이블에 date와 id 열을 클러스터링 키로 추가하려면 다음과 같이 실행합니다:
ALTER TABLE sales
CLUSTER BY (sale_date, sale_id);
8. 클러스터링 키 삭제
필요에 따라 테이블에서 클러스터링 키를 삭제할 수도 있습니다. DROP CLUSTERING KEY 명령을 사용하여 클러스터링 키를 제거할 수 있습니다
ALTER TABLE sales
DROP CLUSTERING KEY;
9. 결론
클러스터링 키는 Snowflake에서 대규모 데이터를 효율적으로 관리하고 쿼리 성능을 최적화하는 중요한 기능입니다. 테이블의 데이터가 자주 쿼리되거나 특정 열을 자주 필터링하는 경우 클러스터링 키를 통해 큰 성능 향상을 기대할 수 있습니다. 하지만 클러스터링은 비용이 소모되므로, 테이블의 특성에 따라 적절하게 적용하는 것이 중요합니다.
Reference
https://docs.snowflake.com/ko/user-guide/tables-clustering-keys#what-is-a-clustering-key
클러스터링 키 및 클러스터링된 테이블 | Snowflake Documentation
단일 클러스터링 키에는 1개 이상의 열 또는 식이 포함될 수 있습니다. 대부분의 테이블에 대해 Snowflake는 키당 최대 3개 또는 4개의 열(또는 식)을 권장합니다. 3~4개 이상의 열을 추가하면 이익보
docs.snowflake.com
'Snowflake' 카테고리의 다른 글
| [Snowflake] Snowflake의 Iceberg 테이블이란? (12) | 2024.10.20 |
|---|---|
| [Snowflake] Snowflake에서 뷰(View) 사용하기 (0) | 2024.10.13 |
| [Snowflake] Snowflake 마이크로 파티션 및 데이터 클러스터링이란? (2) | 2024.10.12 |
| [Snowflake] Snowflake Multi-Cluster Warehouses란? (2) | 2024.10.12 |
| [Snowflake] Snowflake에서 Virtual Warehouse 관리 실습하기 (0) | 2024.10.10 |