이 튜토리얼에서는 LangGraph와 LangChain을 사용해 RAG(Retrieval-Augmented Generation) 시스템을 구축하는 방법을 소개합니다. 이 시스템은 PDF 문서의 정보를 벡터 형태로 저장하고, 질문에 대한 답변을 생성하기 위해 관련된 정보를 검색한 후 LLM을 통해 응답을 생성합니다. 아래 코드와 설명을 통해 LangGraph의 활용 방식과 구현 과정을 살펴보겠습니다.
LangGraph란 무엇인가?
LangGraph는 데이터 처리나 시스템 구성에서 워크플로우를 그래프 형태로 표현하고 제어할 수 있도록 설계된 라이브러리입니다. 특히 LangGraph는 대화형 AI나 RAG 시스템과 같은 다단계 데이터 처리 시스템을 구축하는 데 적합합니다. 각 단계에서의 작업(노드)과 노드 간의 데이터 흐름(엣지)을 정의하여 복잡한 과정을 논리적이고 효율적으로 처리할 수 있도록 도와줍니다.
LangGraph의 주요 특징은 다음과 같습니다:
- 상태(State) 관리: LangGraph는 GraphState와 같은 상태 객체를 통해 각 노드 간 필요한 데이터를 공유하고 상태를 추적할 수 있습니다. 이를 통해 데이터의 흐름을 자연스럽게 관리하고, 각 노드의 역할을 명확하게 분리할 수 있습니다.
- 노드(Node)와 엣지(Edge) 기반 구성: 각 기능이나 작업을 독립적인 노드로 정의하고, 이를 엣지로 연결하여 전체 프로세스를 그래프 형태로 시각화하고 제어할 수 있습니다.
- 확장성: 새로운 기능을 추가하거나 특정 노드의 역할을 변경할 때에도 전체 워크플로우를 수정할 필요 없이 필요한 노드와 엣지만 업데이트하면 되므로 매우 유연하고 확장성이 높습니다.
LangGraph는 특히 RAG 시스템에서 여러 단계를 거쳐 검색 및 응답을 생성하는 과정에서 매우 유용합니다. 이를 통해 복잡한 시스템을 더 직관적이고 효율적으로 구현할 수 있으며, 필요에 따라 손쉽게 유지보수하고 확장할 수 있는 기반을 제공합니다.
구현 목표
- PDF 문서에서 텍스트를 추출하고, 이를 벡터 임베딩으로 변환하여 데이터베이스에 저장
- 사용자의 질문에 가장 유사한 문서를 검색
- 검색된 문서를 바탕으로 LLM을 통해 질문에 답변 생성
1. 코드 구현(VectorDB 만들기)
1. 1환경 설정: OpenAI API 키 지정
먼저 OpenAI API 키를 환경 변수로 설정합니다. OpenAI API를 통해 벡터 임베딩을 생성하고 LLM을 호출할 수 있습니다.
import os
os.environ["OPENAI_API_KEY"] = "OPEN_API_KEY"
1.2 PDF 파일 로드 및 텍스트 분할
PDF 파일을 LangChain의 PyPDFLoader를 이용해 불러온 후, RecursiveCharacterTextSplitter를 통해 텍스트를 분할합니다. 여기서 텍스트 분할을 통해 문서의 정보를 chunk 단위로 나누어 효율적인 검색과 벡터화 작업을 수행할 수 있습니다.
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_chroma import Chroma
pdf_path = "./example.pdf"
loader = PyPDFLoader(pdf_path)
docs = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
1.3 임베딩 생성 및 벡터스토어 저장
OpenAIEmbeddings를 이용해 각 텍스트 chunk의 벡터 임베딩을 생성하고, Chroma를 이용해 벡터스토어에 저장합니다. Chroma는 검색에 최적화된 벡터 데이터베이스로, 이후에 유사 문서 검색을 수행하는 데 사용됩니다.
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(
documents=splits, embedding=embeddings, collection_name="example_db", persist_directory="./example_db"
)2. 코드 구현(Langgraph를 이용한 RAG 체인 만들기)
2.1 GraphState 정의하기
GraphState는 TypedDict를 이용해 시스템 상태를 정의합니다. 여기서 query, db_path, context, answer를 포함하며, 각 단계에서 필요한 정보를 저장하고 공유합니다.
from typing import TypedDict, list
from langchain_core.documents import Document
class GraphState(TypedDict):
query: str
db_path: str
context: list[Document]
answer: str
2.2 Node 함수 정의하기 (get_context() : 유사 문서 검색)
get_context 함수는 벡터스토어에서 사용자의 질문에 가장 유사한 문서 3개를 검색합니다. 검색 결과는 context 필드에 저장되며, 이후 답변 생성 단계에서 사용됩니다.
def get_context(state: GraphState) -> GraphState:
db = Chroma(
persist_directory=state['db_path'],
embedding_function=OpenAIEmbeddings(),
collection_name="example_db",
)
context = db.similarity_search(state["query"], k=3)
return GraphState(context=context)
2.3 Node 함수 정의하기 (generate_answer() : 답변 생성)
generate_answer 함수는 검색된 문서와 사용자의 질문을 바탕으로 LLM을 호출하여 답변을 생성합니다. 여기서 검색된 문서의 텍스트를 모아서 프롬프트에 포함하고, ChatOpenAI를 사용해 LLM을 초기화한 후 응답을 생성합니다.
def generate_answer(state: GraphState) -> GraphState:
context_texts = [doc.page_content for doc in state["context"]]
context_str = "\n\n".join(context_texts)
prompt = ChatPromptTemplate.from_template("Answer the following question based on the provided context:\n\nContext: {context}\n\nQuestion: {query}\nAnswer:")
llm = ChatOpenAI(model='gpt-4o-mini')
chain = prompt | llm | StrOutputParser()
answer = chain.invoke({"query": state["query"], "context": context_str})
return GraphState(answer=answer)
2.4. LangGraph 워크플로우 설정
이제 LangGraph의 StateGraph를 이용해 각 함수를 워크플로우의 노드로 추가하고, 노드 간의 흐름을 연결합니다. 아래와 같이 검색 기능(Retriever)과 답변 생성 기능(LLM_Answer)을 노드로 구성하고, Retriever에서 LLM_Answer로 이어지도록 엣지를 설정합니다.
from langgraph.graph import StateGraph
workflow = StateGraph(GraphState)
workflow.add_node("Retriever", get_context)
workflow.add_node("LLM_Answer", generate_answer)
workflow.add_edge("Retriever", "LLM_Answer")
workflow.set_entry_point("Retriever")
2.5 워크플로우 실행 및 결과 출력
워크플로우를 컴파일하고 실행합니다. RunnableConfig를 통해 설정을 적용하고, 질의응답을 실행하여 결과를 확인할 수 있습니다.
app = workflow.compile()
graph_config = RunnableConfig(recursion_limit=20, configurable={"thread_id": "RAG-Answer"})
query = "해당 문서에서 Abstract의 요지가 무엇인가요?"
inputs = GraphState(query=query, db_path="./example_db")
output = app.invoke(inputs, config=graph_config)
print(output){'query': '해당 문서에서 Abtract의 요지가 무엇인가요?',
'db_path': './example_db',
'context': [Document(metadata={'page': 0, 'source': './example.pdf'}, page_content='USENIX Example Paper\nPekka Nikander\nAalto University\nJane-Ellen Long\nUSENIX Association\nAbstract\nThis is an example for a USENIX paper, in the form\nof an HTML/CSS template. Being heavily self-ref-\nerential, this template illustrates the features in-\ncluded in this template. It is expected that the\nprospective authors using HTML/CSS would create\na new document based on this template, remove\nthe content, and start writing their paper.\nNote that in this template, you may have a mul-\nti-paragraph abstract. However, that it is not nec-\nessarily a good practice. Try to keep your abstract\nin one paragraph, and remember that the optimal\nlength for an abstract is 200-300 words.\n1 Introduction\nFor the purposes of USENIX conference publica-\ntions, the authors, not the USENIX staff, are solely\nresponsible for the content and formatting of their\npaper. The purpose of this template is to help\nthose authors that want to use HTML/CSS to write\ntheir papers. This template has been prepared by'),
Document(metadata={'page': 0, 'source': './example.pdf'}, page_content='USENIX Example Paper\nPekka Nikander\nAalto University\nJane-Ellen Long\nUSENIX Association\nAbstract\nThis is an example for a USENIX paper, in the form\nof an HTML/CSS template. Being heavily self-ref-\nerential, this template illustrates the features in-\ncluded in this template. It is expected that the\nprospective authors using HTML/CSS would create\na new document based on this template, remove\nthe content, and start writing their paper.\nNote that in this template, you may have a mul-\nti-paragraph abstract. However, that it is not nec-\nessarily a good practice. Try to keep your abstract\nin one paragraph, and remember that the optimal\nlength for an abstract is 200-300 words.\n1 Introduction\nFor the purposes of USENIX conference publica-\ntions, the authors, not the USENIX staff, are solely\nresponsible for the content and formatting of their\npaper. The purpose of this template is to help\nthose authors that want to use HTML/CSS to write\ntheir papers. This template has been prepared by'),
Document(metadata={'page': 0, 'source': './example.pdf'}, page_content='USENIX Example Paper\nPekka Nikander\nAalto University\nJane-Ellen Long\nUSENIX Association\nAbstract\nThis is an example for a USENIX paper, in the form\nof an HTML/CSS template. Being heavily self-ref-\nerential, this template illustrates the features in-\ncluded in this template. It is expected that the\nprospective authors using HTML/CSS would create\na new document based on this template, remove\nthe content, and start writing their paper.\nNote that in this template, you may have a mul-\nti-paragraph abstract. However, that it is not nec-\nessarily a good practice. Try to keep your abstract\nin one paragraph, and remember that the optimal\nlength for an abstract is 200-300 words.\n1 Introduction\nFor the purposes of USENIX conference publica-\ntions, the authors, not the USENIX staff, are solely\nresponsible for the content and formatting of their\npaper. The purpose of this template is to help\nthose authors that want to use HTML/CSS to write\ntheir papers. This template has been prepared by')],
'answer': '해당 문서에서 Abstract의 요지는 USENIX 회의 논문 작성을 위한 HTML/CSS 템플릿을 제공하고, 이 템플릿의 사용 방법과 작성 시 유의사항을 안내하는 것입니다. 특히, 저자들은 이 템플릿을 기반으로 새로운 문서를 작성하고, 내용을 제거한 후 자신의 논문을 작성해야 하며, 여러 문단으로 구성된 초록은 좋지 않은 관행이므로 가능한 한 한 문단으로 작성하고, 최적의 길이는 200-300 단어임을 강조하고 있습니다.'}
2.6 그래프 시각화 하기
from IPython.display import Image, display
display(Image(app.get_graph().draw_mermaid_png()))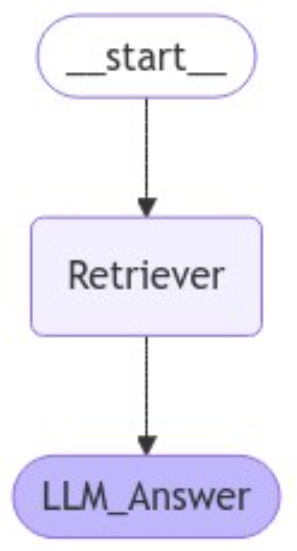
결론
이 튜토리얼에서는 LangGraph를 이용해 RAG 시스템을 구성하고, LangChain을 통해 PDF 문서 검색 및 응답 생성을 완성했습니다. 이를 통해 LangGraph 기반의 워크플로우 구성 방식이 RAG 시스템에서 어떻게 유용하게 활용될 수 있는지 이해할 수 있습니다.