반응형
LLM이란?
대형 언어 모델(LLM:Large Language Model)은 방대한 양의 데이터를 기반으로 사전 학습된 초대형 딥러닝 모델입니다. 트랜스포머의 인코더 구조를 통해 텍스트의 기본 문법, 언어 및 지식을 이해하고, 디코더 구조를 통해 문장을 생성합니다.
LLM 목적
LLM은 자연어 텍스트의 말뭉치를 분석하여 문법, 구문 및 의미적 관계를 이해하여 일관성 있고 맥락에 적합한 응답을 생성하는 것이 목적입니다.
LLM 구조
트랜스포머 모델을 기본으로 하고 있으며
- 인코더를 기본으로 BERT 계열 모델이 발전하였고 자연어를 이해하는데 강점을 두고 있습니다.
- 디코더를 기본으로 GPT 계열 모델이 발전하였고 자연어를 생성하는데 강점을 두고 있습니다.

RAG(Retrieval Augmented Generation) 시스템이란?
Retrieval Augmented Generation(검색 증강 생성)은 외부 데이터를 이용하여 대형 언어 모델(LLM)을 사용할 수 있도록 만든 시스템 입니다.
RAG 목적
질문과 함께 외부 데이터를 사용하여 원하는 답을 정확하게 얻을 수 있도록 만드는 것입니다.
RAG 장점
- 확장된 데이터를 활용한 검색을 가능하게 합니다.
- 개인화 데이터를 활용한 검색을 가능하게 합니다.
- 출처 기반 답변을 통해 할루시네이션을 최소화 할 수 있습니다.
RAG 구조
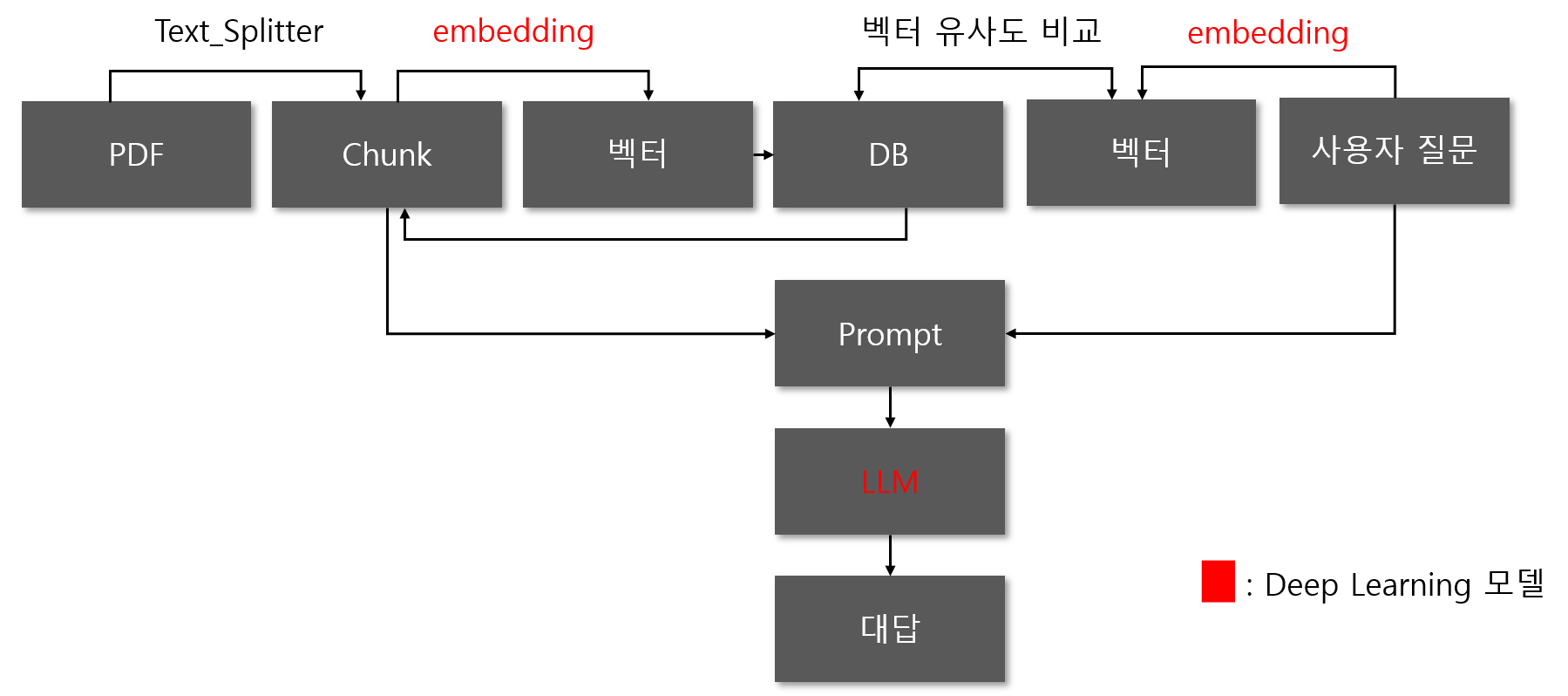
- Data Load : 데이터를 읽습니다.
- Text Split : 텍스트를 Chunk 단위로 나눕니다.
- Embedding : Chunk를 벡터 형태로 임베딩 합니다.
- VectorDB : 임베딩 된 벡터를 VectorDB에 저장합니다.
- Retrieval : VectorDB에 저장된 데이터 중 질문과 유사성이 높은 Reference 데이터를 찾습니다.
- LLM : Reference 데이터와 질문 데이터를 LLM에 input으로 넣습니다.
- 대답 : LLM의 Output을 파싱하여 답을 얻습니다.
랭체인(Langchain)이란?
RAG 시스템을 구축하는데 필요한 함수들이 내장되어 있어 대형 언어 모델(LLM)을 기반으로 하는 어플리케이션을 쉽고 빠르게 개발하기 위해 만들어진 프레임워크입니다.
랭체인 사용 방법
$pip install langchain
$pip install langchain-community
$pip install langchain-corefrom langchain_community.document_loaders import WebBaseLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains import create_retrieval_chain위와 같이 RAG 시스템을 만들기 위한 패키지를 불러와 사용합니다.
Reference
https://arxiv.org/abs/1706.03762
https://aws.amazon.com/ko/what-is/large-language-model/
반응형